これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
クラスターの管理
- 1: クラスター管理の概要
- 2: 証明書
- 3: リソースの管理
- 4: クラスターのネットワーク
- 5: ロギングのアーキテクチャ
- 6: システムログ
- 7: Kubernetesのプロキシー
- 8: アドオンのインストール
1 - クラスター管理の概要
このページはKubernetesクラスターの作成や管理者向けの内容です。Kubernetesのコアコンセプトについてある程度精通していることを前提とします。
クラスターのプランニング
Kubernetesクラスターの計画、セットアップ、設定の例を知るには設定のガイドを参照してください。この記事で列挙されているソリューションはディストリビューション と呼ばれます。
ガイドを選択する前に、いくつかの考慮事項を挙げます。
- ユーザーのコンピューター上でKubernetesを試したいでしょうか、それとも高可用性のあるマルチノードクラスターを構築したいでしょうか?あなたのニーズにあったディストリビューションを選択してください。
- もしあなたが高可用性を求める場合、 複数ゾーンにまたがるクラスターの設定について学んでください。
- Google Kubernetes EngineのようなホストされているKubernetesクラスターを使用するのか、それとも自分自身でクラスターをホストするのでしょうか?
- 使用するクラスターはオンプレミスなのか、それともクラウド(IaaS) でしょうか?Kubernetesはハイブリッドクラスターを直接サポートしていません。その代わりユーザーは複数のクラスターをセットアップできます。
- Kubernetesを 「ベアメタル」なハードウェア上で稼働させますか?それとも仮想マシン(VMs) 上で稼働させますか?
- もしオンプレミスでKubernetesを構築する場合、どのネットワークモデルが最適か検討してください。
- ただクラスターを稼働させたいだけでしょうか、それともKubernetesプロジェクトのコードの開発を行いたいでしょうか?もし後者の場合、開発が進行中のディストリビューションを選択してください。いくつかのディストリビューションはバイナリリリースのみ使用していますが、多くの選択肢があります。
- クラスターを稼働させるのに必要なコンポーネントについてよく理解してください。
注意: 全てのディストリビューションがアクティブにメンテナンスされている訳ではありません。最新バージョンのKubernetesでテストされたディストリビューションを選択してください。
クラスターの管理
クラスターをセキュアにする
-
Certificatesでは、異なるツールチェインを使用して証明書を作成する方法を説明します。
-
Kubernetes コンテナの環境では、Kubernetesノード上でのKubeletが管理するコンテナの環境について説明します。
-
Kubernetes APIへのアクセス制御では、Kubernetesで自身のAPIに対するアクセスコントロールがどのように実装されているかを説明します。
-
認証では、様々な認証オプションを含むKubernetesでの認証について説明します。
-
認可では、認証とは別に、HTTPリクエストの処理方法を制御します。
-
アドミッションコントローラーの使用では、認証と認可の後にKubernetes APIに対するリクエストをインターセプトするプラグインについて説明します。
-
Kubernetesクラスターでのsysctlの使用では、管理者向けにカーネルパラメーターを設定するため
sysctlコマンドラインツールの使用方法について解説します。 -
クラスターの監査では、Kubernetesの監査ログの扱い方について解説します。
kubeletをセキュアにする
オプションのクラスターサービス
-
DNSのインテグレーションでは、DNS名をKubernetes Serviceに直接名前解決する方法を解説します。
-
クラスターアクティビィのロギングと監視では、Kubernetesにおけるロギングがどのように行われ、どう実装されているかについて解説します。
2 - 証明書
クライアント証明書認証を使用する場合、easyrsaやopenssl、cfsslを用いて、手動で証明書を生成できます。
easyrsa
easyrsaを用いると、クラスターの証明書を手動で生成できます。
-
パッチを当てたバージョンのeasyrsa3をダウンロードして解凍し、初期化します。
curl -LO https://storage.googleapis.com/kubernetes-release/easy-rsa/easy-rsa.tar.gz tar xzf easy-rsa.tar.gz cd easy-rsa-master/easyrsa3 ./easyrsa init-pki -
新しい認証局(CA)を生成します。
--batchは自動モードを設定し、--req-cnはCAの新しいルート証明書の共通名(CN)を指定します。./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass -
サーバー証明書と鍵を生成します。 引数
--subject-alt-nameは、APIサーバーへのアクセスに使用できるIPおよびDNS名を設定します。MASTER_CLUSTER_IPは通常、APIサーバーとコントローラーマネージャーコンポーネントの両方で引数--service-cluster-ip-rangeとして指定されるサービスCIDRの最初のIPです。 引数--daysは、証明書の有効期限が切れるまでの日数を設定するために使われます。 以下の例は、デフォルトのDNSドメイン名としてcluster.localを使用していることを前提とします。./easyrsa --subject-alt-name="IP:${MASTER_IP},"\ "IP:${MASTER_CLUSTER_IP},"\ "DNS:kubernetes,"\ "DNS:kubernetes.default,"\ "DNS:kubernetes.default.svc,"\ "DNS:kubernetes.default.svc.cluster,"\ "DNS:kubernetes.default.svc.cluster.local" \ --days=10000 \ build-server-full server nopass -
pki/ca.crt、pki/issued/server.crt、pki/private/server.keyをディレクトリーにコピーします。 -
以下のパラメーターを、APIサーバーの開始パラメーターとして追加します。
--client-ca-file=/yourdirectory/ca.crt --tls-cert-file=/yourdirectory/server.crt --tls-private-key-file=/yourdirectory/server.key
openssl
opensslはクラスターの証明書を手動で生成できます。
-
2048ビットのca.keyを生成します。
openssl genrsa -out ca.key 2048 -
ca.keyに応じて、ca.crtを生成します。証明書の有効期間を設定するには、-daysを使用します。
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt -
2048ビットのserver.keyを生成します。
openssl genrsa -out server.key 2048 -
証明書署名要求(CSR)を生成するための設定ファイルを生成します。 ファイル(例:
csr.conf)に保存する前に、かぎ括弧で囲まれた値(例:<MASTER_IP>)を必ず実際の値に置き換えてください。MASTER_CLUSTER_IPの値は、前節で説明したAPIサーバーのサービスクラスターIPであることに注意してください。 以下の例は、デフォルトのDNSドメイン名としてcluster.localを使用していることを前提とします。[ req ] default_bits = 2048 prompt = no default_md = sha256 req_extensions = req_ext distinguished_name = dn [ dn ] C = <country> ST = <state> L = <city> O = <organization> OU = <organization unit> CN = <MASTER_IP> [ req_ext ] subjectAltName = @alt_names [ alt_names ] DNS.1 = kubernetes DNS.2 = kubernetes.default DNS.3 = kubernetes.default.svc DNS.4 = kubernetes.default.svc.cluster DNS.5 = kubernetes.default.svc.cluster.local IP.1 = <MASTER_IP> IP.2 = <MASTER_CLUSTER_IP> [ v3_ext ] authorityKeyIdentifier=keyid,issuer:always basicConstraints=CA:FALSE keyUsage=keyEncipherment,dataEncipherment extendedKeyUsage=serverAuth,clientAuth subjectAltName=@alt_names -
設定ファイルに基づいて、証明書署名要求を生成します。
openssl req -new -key server.key -out server.csr -config csr.conf -
ca.key、ca.crt、server.csrを使用してサーバー証明書を生成します。
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \ -CAcreateserial -out server.crt -days 10000 \ -extensions v3_ext -extfile csr.conf -sha256 -
証明書を表示します。
openssl x509 -noout -text -in ./server.crt
最後にAPIサーバーの起動パラメーターに、同様のパラメーターを追加します。
cfssl
cfsslも証明書を生成するためのツールです。
-
以下のように、ダウンロードして解凍し、コマンドラインツールを用意します。 使用しているハードウェアアーキテクチャやcfsslのバージョンに応じて、サンプルコマンドの調整が必要な場合があります。
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl chmod +x cfssl curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson chmod +x cfssljson curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo chmod +x cfssl-certinfo -
アーティファクトを保持するディレクトリーを生成し、cfsslを初期化します。
mkdir cert cd cert ../cfssl print-defaults config > config.json ../cfssl print-defaults csr > csr.json -
CAファイルを生成するためのJSON設定ファイル(例:
ca-config.json)を生成します。{ "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } -
CA証明書署名要求(CSR)用のJSON設定ファイル(例:
ca-csr.json)を生成します。 かぎ括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。{ "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names":[{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
CA鍵(
ca-key.pem)と証明書(ca.pem)を生成します。../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca -
APIサーバーの鍵と証明書を生成するためのJSON設定ファイル(例:
server-csr.json)を生成します。 かぎ括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。MASTER_CLUSTER_IPの値は、前節で説明したAPIサーバーのサービスクラスターIPです。 以下の例は、デフォルトのDNSドメイン名としてcluster.localを使用していることを前提とします。{ "CN": "kubernetes", "hosts": [ "127.0.0.1", "<MASTER_IP>", "<MASTER_CLUSTER_IP>", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster", "kubernetes.default.svc.cluster.local" ], "key": { "algo": "rsa", "size": 2048 }, "names": [{ "C": "<country>", "ST": "<state>", "L": "<city>", "O": "<organization>", "OU": "<organization unit>" }] } -
APIサーバーの鍵と証明書を生成します。デフォルトでは、それぞれ
server-key.pemとserver.pemというファイルに保存されます。../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \ --config=ca-config.json -profile=kubernetes \ server-csr.json | ../cfssljson -bare server
自己署名CA証明書の配布
クライアントノードは、自己署名CA証明書を有効だと認識しないことがあります。 プロダクション用でない場合や、会社のファイアウォールの背後で実行する場合は、自己署名CA証明書をすべてのクライアントに配布し、有効な証明書のローカルリストを更新できます。
各クライアントで、以下の操作を実行します。
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
証明書API
certificates.k8s.ioAPIを用いることで、こちらのドキュメントにあるように、認証に使用するx509証明書をプロビジョニングすることができます。
3 - リソースの管理
アプリケーションをデプロイし、Serviceを介して外部に公開できました。さて、どうしますか?Kubernetesは、スケーリングや更新など、アプリケーションのデプロイを管理するための多くのツールを提供します。 我々が取り上げる機能についての詳細は設定ファイルとラベルについて詳細に説明します。
リソースの設定を管理する
多くのアプリケーションではDeploymentやServiceなど複数のリソースの作成を要求します。複数のリソースの管理は、同一のファイルにひとまとめにしてグループ化すると簡単になります(YAMLファイル内で---で区切る)。
例えば:

apiVersion: v1
kind: Service
metadata:
name: my-nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
複数のリソースは単一のリソースと同様の方法で作成できます。
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
リソースは、ファイル内に記述されている順番通りに作成されます。そのため、Serviceを最初に指定するのが理想です。スケジューラーがServiceに関連するPodを、Deploymentなどのコントローラーによって作成されるときに確実に拡散できるようにするためです。
kubectl applyもまた、複数の-fによる引数指定を許可しています。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
個別のファイルに加えて、-fの引数としてディレクトリ名も指定できます:
kubectl apply -f https://k8s.io/examples/application/nginx/
kubectlは.yaml、.yml、.jsonといったサフィックスの付くファイルを読み込みます。
同じマイクロサービス、アプリケーションティアーのリソースは同一のファイルにまとめ、アプリケーションに関するファイルをグループ化するために、それらのファイルを同一のディレクトリに配備するのを推奨します。アプリケーションのティアーがDNSを通じて互いにバインドされると、アプリケーションスタックの全てのコンポーネントをひとまとめにして簡単にデプロイできます。
リソースの設定ソースとして、URLも指定できます。githubから取得した設定ファイルから直接手軽にデプロイができます:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/website/master/content/en/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
kubectlによる一括操作
kubectlが一括して実行できる操作はリソースの作成のみではありません。作成済みのリソースの削除などの他の操作を実行するために、設定ファイルからリソース名を取得することができます。
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
2つのリソースだけを削除する場合には、コマンドラインでリソース/名前というシンタックスを使うことで簡単に指定できます。
kubectl delete deployments/my-nginx services/my-nginx-svc
さらに多くのリソースに対する操作では、リソースをラベルでフィルターするために-lや--selectorを使ってセレクター(ラベルクエリ)を指定するのが簡単です:
kubectl delete deployment,services -l app=nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
kubectlは同様のシンタックスでリソース名を出力するので、$()やxargsを使ってパイプで操作するのが容易です:
kubectl get $(kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
上記のコマンドで、最初にexamples/application/nginx/配下でリソースを作成し、-o nameという出力フォーマットにより、作成されたリソースの名前を表示します(各リソースをresource/nameという形式で表示)。そして"service"のみgrepし、kubectl getを使って表示させます。
あるディレクトリ内の複数のサブディレクトリをまたいでリソースを管理するような場合、--filename,-fフラグと合わせて--recursiveや-Rを指定することでサブディレクトリに対しても再帰的に操作が可能です。
例えば、開発環境用に必要な全てのマニフェストをリソースタイプによって整理しているproject/k8s/developmentというディレクトリがあると仮定します。
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
デフォルトでは、project/k8s/developmentにおける一括操作は、どのサブディレクトリも処理せず、ディレクトリの第1階層で処理が止まります。下記のコマンドによってこのディレクトリ配下でリソースを作成しようとすると、エラーが発生します。
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename (.json|.yaml|.yml|stdin)
代わりに、下記のように--filename,-fフラグと合わせて--recursiveや-Rを指定してください:
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
--recursiveフラグはkubectl {create,get,delete,describe,rollout}などのような--filename,-fフラグを扱うどの操作でも有効です。
また、--recursiveフラグは複数の-fフラグの引数を指定しても有効です。
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
kubectlについてさらに知りたい場合は、コマンドラインツール(kubectl)を参照してください。
ラベルを有効に使う
これまで取り上げた例では、リソースに対して最大1つのラベルを適用してきました。リソースのセットを他のセットと区別するために、複数のラベルが必要な状況があります。
例えば、異なるアプリケーション間では、異なるappラベルを使用したり、ゲストブックの例のようなマルチティアーのアプリケーションでは、各ティアーを区別する必要があります。frontendというティアーでは下記のラベルを持ちます。:
labels:
app: guestbook
tier: frontend
Redisマスターやスレーブでは異なるtierラベルを持ち、加えてroleラベルも持つことでしょう。:
labels:
app: guestbook
tier: backend
role: master
そして
labels:
app: guestbook
tier: backend
role: slave
ラベルを使用すると、ラベルで指定された任意の次元に沿ってリソースを分割できます。
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-slave-2q2yf 1/1 Running 0 1m guestbook backend slave
guestbook-redis-slave-qgazl 1/1 Running 0 1m guestbook backend slave
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp=guestbook,role=slave
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
Canary deployments カナリアデプロイ
複数のラベルが必要な他の状況として、異なるリリース間でのDeploymentや、同一コンポーネントの設定を区別することが挙げられます。よく知られたプラクティスとして、本番環境の実際のトラフィックを受け付けるようにするために、新しいリリースを完全にロールアウトする前に、新しいカナリア版のアプリケーションを過去のリリースと合わせてデプロイする方法があります。
例えば、異なるリリースバージョンを分けるためにtrackラベルを使用できます。
主要な安定板のリリースではtrackラベルにstableという値をつけることがあるでしょう。:
name: frontend
replicas: 3
...
labels:
app: guestbook
tier: frontend
track: stable
...
image: gb-frontend:v3
そして2つの異なるPodのセットを上書きしないようにするため、trackラベルに異なる値を持つ(例: canary)ようなguestbookフロントエンドの新しいリリースを作成できます。
name: frontend-canary
replicas: 1
...
labels:
app: guestbook
tier: frontend
track: canary
...
image: gb-frontend:v4
frontend Serviceは、トラフィックを両方のアプリケーションにリダイレクトさせるために、両方のアプリケーションに共通したラベルのサブセットを選択して両方のレプリカを扱えるようにします。:
selector:
app: guestbook
tier: frontend
安定版とカナリア版リリースで本番環境の実際のトラフィックを転送する割合を決めるため、双方のレプリカ数を変更できます(このケースでは3対1)。 最新版のリリースをしても大丈夫な場合、安定版のトラックを新しいアプリケーションにして、カナリア版を削除します。
さらに具体的な例については、tutorial of deploying Ghostを参照してください。
ラベルの更新
新しいリソースを作成する前に、既存のPodと他のリソースのラベルの変更が必要な状況があります。これはkubectl labelで実行できます。
例えば、全てのnginx Podを frontendティアーとしてラベル付けするには、下記のコマンドを実行するのみです。
kubectl label pods -l app=nginx tier=fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
これは最初に"app=nginx"というラベルのついたPodをフィルターし、そのPodに対して"tier=fe"というラベルを追加します。 ラベル付けしたPodを確認するには、下記のコマンドを実行してください。
kubectl get pods -l app=nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
このコマンドでは"app=nginx"というラベルのついた全てのPodを出力し、Podのtierという項目も表示します(-Lまたは--label-columnsで指定)。
さらなる情報は、ラベルやkubectl labelを参照してください。
アノテーションの更新
リソースに対してアノテーションを割り当てたい状況があります。アノテーションは、ツール、ライブラリなどのAPIクライアントによって取得するための任意の非識別メタデータです。アノテーションの割り当てはkubectl annotateで可能です。例:
kubectl annotate pods my-nginx-v4-9gw19 description='my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
さらなる情報は、アノテーション や、kubectl annotateを参照してください。
アプリケーションのスケール
アプリケーションの負荷が増減するとき、kubectlを使って簡単にスケールできます。例えば、nginxのレプリカを3から1に減らす場合、下記を実行します:
kubectl scale deployment/my-nginx --replicas=1
deployment.apps/my-nginx scaled
実行すると、Deploymentによって管理されるPod数が1となります。
kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
システムに対してnginxのレプリカ数を自動で選択させるには、下記のように1から3の範囲で指定します。:
kubectl autoscale deployment/my-nginx --min=1 --max=3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
実行すると、nginxのレプリカは必要に応じて自動でスケールアップ、スケールダウンします。
さらなる情報は、kubectl scale、kubectl autoscale and horizontal pod autoscalerを参照してください。
リソースの直接的アップデート
場合によっては、作成したリソースに対して処理を中断させずに更新を行う必要があります。
kubectl apply
開発者が設定するリソースをコードとして管理しバージョニングも行えるように、設定ファイルのセットをソースによって管理する方法が推奨されています。
この場合、クラスターに対して設定の変更をプッシュするためにkubectl applyを使用できます。
このコマンドは、リソース設定の過去のバージョンと、今適用した変更を比較し、差分に現れないプロパティーに対して上書き変更することなくクラスターに適用させます。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
注意として、前回の変更適用時からの設定の変更内容を決めるため、kubectl applyはリソースに対してアノテーションを割り当てます。変更が実施されるとkubectl applyは、1つ前の設定内容と、今回変更しようとする入力内容と、現在のリソースの設定との3つの間で変更内容の差分をとります。
現在、リソースはこのアノテーションなしで作成されました。そのため、最初のkubectl paplyの実行においては、与えられた入力と、現在のリソースの設定の2つの間の差分が取られ、フォールバックします。この最初の実行の間、リソースが作成された時にプロパティーセットの削除を検知できません。この理由により、プロパティーの削除はされません。
kubectl applyの実行後の全ての呼び出しや、kubectl replaceやkubectl editなどの設定を変更する他のコマンドではアノテーションを更新します。kubectl applyした後の全ての呼び出しにおいて3-wayの差分取得によってプロパティの検知と削除を実施します。
kubectl edit
その他に、kubectl editによってリソースの更新もできます。:
kubectl edit deployment/my-nginx
このコマンドは、最初にリソースをgetし、テキストエディタでリソースを編集し、更新されたバージョンでリソースをapplyします。:
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# yamlファイルを編集し、ファイルを保存します。
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
このコマンドによってより重大な変更を簡単に行えます。注意として、あなたのEDITORやKUBE_EDITORといった環境変数も指定できます。
さらなる情報は、kubectl editを参照してください。
kubectl patch
APIオブジェクトの更新にはkubectl patchを使うことができます。このコマンドはJSON patch、JSON merge patch、戦略的merge patchをサポートしています。
kubectl patchを使ったAPIオブジェクトの更新やkubectl patchを参照してください。
破壊的なアップデート
一度初期化された後、更新できないようなリソースフィールドの更新が必要な場合や、Deploymentによって作成され、壊れている状態のPodを修正するなど、再帰的な変更を即座に行いたい場合があります。このようなフィールドを変更するため、リソースの削除と再作成を行うreplace --forceを使用してください。このケースでは、シンプルに元の設定ファイルを修正するのみです。:
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
サービス停止なしでアプリケーションを更新する
ある時点で、前述したカナリアデプロイのシナリオにおいて、新しいイメージやイメージタグを指定することによって、デプロイされたアプリケーションを更新が必要な場合があります。kubectlではいくつかの更新操作をサポートしており、それぞれの操作が異なるシナリオに対して適用可能です。
ここでは、Deploymentを使ってアプリケーションの作成と更新についてガイドします。
まずnginxのバージョン1.14.2を稼働させていると仮定します。:
kubectl create deployment my-nginx --image=nginx:1.14.2
deployment.apps/my-nginx created
レプリカ数を3にします(新旧のリビジョンは混在します)。:
kubectl scale deployment my-nginx --current-replicas=1 --replicas=3
deployment.apps/my-nginx scaled
バージョン1.16.1に更新するには、上述したkubectlコマンドを使って.spec.template.spec.containers[0].imageの値をnginx:1.14.2からnginx:1.16.1に変更するだけでできます。
kubectl edit deployment/my-nginx
できました!Deploymentはデプロイされたnginxのアプリケーションを宣言的にプログレッシブに更新します。更新途中では、決まった数の古いレプリカのみダウンし、一定数の新しいレプリカが希望するPod数以上作成されても良いことを保証します。詳細について学ぶにはDeployment pageを参照してください。
次の項目
- アプリケーションの調査とデバッグのための
kubectlの使用方法について学んでください。 - 設定のベストプラクティスとTIPSを参照してください。
4 - クラスターのネットワーク
ネットワークはKubernetesにおける中心的な部分ですが、どのように動作するかを正確に理解することは難解な場合もあります。 Kubernetesには、4つの異なる対応すべきネットワークの問題があります:
- 高度に結合されたコンテナ間の通信: これは、Podおよび
localhost通信によって解決されます。 - Pod間の通信: 本ドキュメントの主な焦点です。
- Podからサービスへの通信: これはServiceでカバーされています。
- 外部からサービスへの通信: これはServiceでカバーされています。
Kubernetesは、言ってしまえばアプリケーション間でマシンを共有するためのものです。通常、マシンを共有するには、2つのアプリケーションが同じポートを使用しないようにする必要があります。 複数の開発者間でのポートの調整は、大規模に行うことが非常に難しく、ユーザーが制御できないクラスターレベルの問題に直面することになります。
動的ポート割り当てはシステムに多くの複雑さをもたらします。すべてのアプリケーションはポートをフラグとして受け取らなければならない、APIサーバーは設定ブロックに動的ポート番号を挿入する方法を知っていなければならない、各サービスは互いを見つける方法を知らなければならない、などです。Kubernetesはこれに対処するのではなく、別のアプローチを取ります。
Kubernetesネットワークモデルについては、こちらを参照してください。
Kubernetesネットワークモデルの実装方法
ネットワークモデルは、各ノード上のコンテナランタイムによって実装されます。最も一般的なコンテナランタイムは、Container Network Interface (CNI)プラグインを使用して、ネットワークとセキュリティ機能を管理します。CNIプラグインは、さまざまなベンダーから多数提供されています。これらの中には、ネットワークインターフェースの追加と削除という基本的な機能のみを提供するものもあれば、他のコンテナオーケストレーションシステムとの統合、複数のCNIプラグインの実行、高度なIPAM機能など、より洗練されたソリューションを提供するものもあります。
Kubernetesがサポートするネットワークアドオンの非網羅的なリストについては、このページを参照してください。
次の項目
ネットワークモデルの初期設計とその根拠、および将来の計画については、ネットワーク設計ドキュメントで詳細に説明されています。
5 - ロギングのアーキテクチャ
アプリケーションログは、アプリケーション内で何が起こっているかを理解するのに役立ちます。ログは、問題のデバッグとクラスターアクティビティの監視に特に役立ちます。最近のほとんどのアプリケーションには、何らかのロギングメカニズムがあります。同様に、コンテナエンジンはロギングをサポートするように設計されています。コンテナ化されたアプリケーションで、最も簡単で最も採用されているロギング方法は、標準出力と標準エラーストリームへの書き込みです。
ただし、コンテナエンジンまたはランタイムによって提供されるネイティブ機能は、たいていの場合、完全なロギングソリューションには十分ではありません。
たとえば、コンテナがクラッシュした場合やPodが削除された場合、またはノードが停止した場合に、アプリケーションのログにアクセスしたい場合があります。
クラスターでは、ノードやPod、またはコンテナに関係なく、ノードに個別のストレージとライフサイクルが必要です。この概念は、クラスターレベルロギング と呼ばれます。
クラスターレベルロギングのアーキテクチャでは、ログを保存、分析、およびクエリするための個別のバックエンドが必要です。Kubernetesは、ログデータ用のネイティブストレージソリューションを提供していません。代わりに、Kubernetesに統合される多くのロギングソリューションがあります。次のセクションでは、ノードでログを処理および保存する方法について説明します。
Kubernetesでの基本的なロギング
この例では、1秒に1回標準出力ストリームにテキストを書き込むコンテナを利用する、Pod specificationを使います。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
このPodを実行するには、次のコマンドを使用します:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
出力は次のようになります:
pod/counter created
ログを取得するには、以下のようにkubectl logsコマンドを使用します:
kubectl logs counter
出力は次のようになります:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
コンテナの以前のインスタンスからログを取得するために、kubectl logs --previousを使用できます。Podに複数のコンテナがある場合は、次のように-cフラグでコマンドにコンテナ名を追加することで、アクセスするコンテナのログを指定します。
kubectl logs counter -c count
詳細については、kubectl logsドキュメントを参照してください。
ノードレベルでのロギング
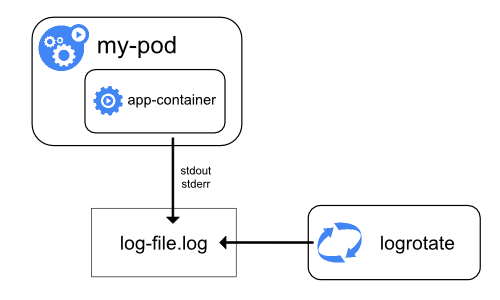
コンテナエンジンは、生成された出力を処理して、コンテナ化されたアプリケーションのstdoutとstderrストリームにリダイレクトします。たとえば、Dockerコンテナエンジンは、これら2つのストリームをロギングドライバーにリダイレクトします。ロギングドライバーは、JSON形式でファイルに書き込むようにKubernetesで設定されています。
デフォルトでは、コンテナが再起動すると、kubeletは1つの終了したコンテナをログとともに保持します。Podがノードから削除されると、対応する全てのコンテナが、ログとともに削除されます。
ノードレベルロギングでの重要な考慮事項は、ノードで使用可能な全てのストレージをログが消費しないように、ログローテーションを実装することです。Kubernetesはログのローテーションを担当しませんが、デプロイツールでそれに対処するソリューションを構築する必要があります。たとえば、kube-up.shスクリプトによってデプロイされたKubernetesクラスターには、1時間ごとに実行するように構成されたlogrotateツールがあります。アプリケーションのログを自動的にローテーションするようにコンテナランタイムを構築することもできます。
例として、configure-helper scriptに対応するスクリプトであるkube-up.shが、どのようにGCPでCOSイメージのロギングを構築しているかについて、詳細な情報を見つけることができます。
CRIコンテナランタイムを使用する場合、kubeletはログのローテーションとログディレクトリ構造の管理を担当します。kubeletはこの情報をCRIコンテナランタイムに送信し、ランタイムはコンテナログを指定された場所に書き込みます。2つのkubeletパラメーター、container-log-max-sizeとcontainer-log-max-filesをkubelet設定ファイルで使うことで、各ログファイルの最大サイズと各コンテナで許可されるファイルの最大数をそれぞれ設定できます。
基本的なロギングの例のように、kubectl logsを実行すると、ノード上のkubeletがリクエストを処理し、ログファイルから直接読み取ります。kubeletはログファイルの内容を返します。
kubectl logsで利用可能になります。例えば、10MBのファイルがある場合、logrotateによるローテーションが実行されると、2つのファイルが存在することになります: 1つはサイズが10MBのファイルで、もう1つは空のファイルです。この例では、kubectl logsは最新のログファイルの内容、つまり空のレスポンスを返します。
システムコンポーネントログ
システムコンポーネントには、コンテナ内で実行されるものとコンテナ内で実行されないものの2種類があります。例えば以下のとおりです。
- Kubernetesスケジューラーとkube-proxyはコンテナ内で実行されます。
- kubeletとコンテナランタイムはコンテナ内で実行されません。
systemdを搭載したマシンでは、kubeletとコンテナランタイムがjournaldに書き込みます。systemdが存在しない場合、kubeletとコンテナランタイムはvar/logディレクトリ内の.logファイルに書き込みます。コンテナ内のシステムコンポーネントは、デフォルトのロギングメカニズムを迂回して、常に/var/logディレクトリに書き込みます。それらはklogというロギングライブラリを使用します。これらのコンポーネントのロギングの重大性に関する規則は、development docs on loggingに記載されています。
コンテナログと同様に、/var/logディレクトリ内のシステムコンポーネントログはローテーションする必要があります。kube-up.shスクリプトによって生成されたKubernetesクラスターでは、これらのログは、logrotateツールによって毎日、またはサイズが100MBを超えた時にローテーションされるように設定されています。
クラスターレベルロギングのアーキテクチャ
Kubernetesはクラスターレベルロギングのネイティブソリューションを提供していませんが、検討可能な一般的なアプローチがいくつかあります。ここにいくつかのオプションを示します:
- 全てのノードで実行されるノードレベルのロギングエージェントを使用します。
- アプリケーションのPodにログインするための専用のサイドカーコンテナを含めます。
- アプリケーション内からバックエンドに直接ログを送信します。
ノードロギングエージェントの使用
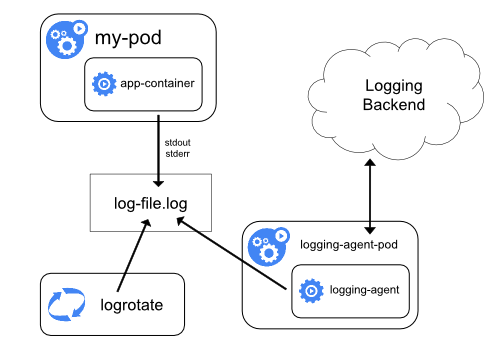
各ノードに ノードレベルのロギングエージェント を含めることで、クラスターレベルロギングを実装できます。ロギングエージェントは、ログを公開したり、ログをバックエンドに送信したりする専用のツールです。通常、ロギングエージェントは、そのノード上の全てのアプリケーションコンテナからのログファイルを含むディレクトリにアクセスできるコンテナです。
ロギングエージェントは全てのノードで実行する必要があるため、エージェントをDaemonSetとして実行することをおすすめします。
ノードレベルのロギングは、ノードごとに1つのエージェントのみを作成し、ノードで実行されているアプリケーションに変更を加える必要はありません。
コンテナはstdoutとstderrに書き込みますが、合意された形式はありません。ノードレベルのエージェントはこれらのログを収集し、集約のために転送します。
ロギングエージェントでサイドカーコンテナを使用する
サイドカーコンテナは、次のいずれかの方法で使用できます:
- サイドカーコンテナは、アプリケーションログを自身の
stdoutにストリーミングします。 - サイドカーコンテナは、アプリケーションコンテナからログを取得するように設定されたロギングエージェントを実行します。
ストリーミングサイドカーコンテナ
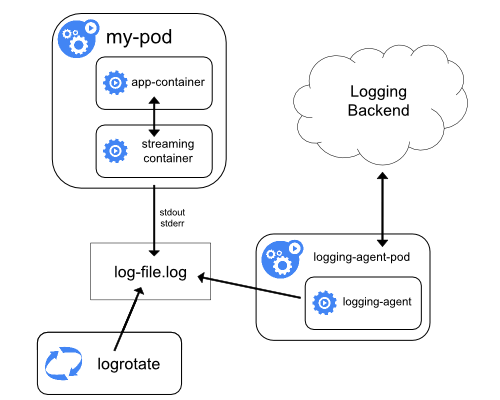
サイドカーコンテナに自身のstdoutやstderrストリームへの書き込みを行わせることで、各ノードですでに実行されているkubeletとロギングエージェントを利用できます。サイドカーコンテナは、ファイル、ソケット、またはjournaldからログを読み取ります。各サイドカーコンテナは、ログを自身のstdoutまたはstderrストリームに出力します。
このアプローチにより、stdoutまたはstderrへの書き込みのサポートが不足している場合も含め、アプリケーションのさまざまな部分からいくつかのログストリームを分離できます。ログのリダイレクトの背後にあるロジックは最小限であるため、大きなオーバーヘッドにはなりません。さらに、stdoutとstderrはkubeletによって処理されるため、kubectl logsのような組み込みツールを使用できます。
たとえば、Podは単一のコンテナを実行し、コンテナは2つの異なる形式を使用して2つの異なるログファイルに書き込みます。Podの構成ファイルは次のとおりです:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
両方のコンポーネントをコンテナのstdoutストリームにリダイレクトできたとしても、異なる形式のログエントリを同じログストリームに書き込むことはおすすめしません。代わりに、2つのサイドカーコンテナを作成できます。各サイドカーコンテナは、共有ボリュームから特定のログファイルを追跡し、ログを自身のstdoutストリームにリダイレクトできます。
2つのサイドカーコンテナを持つPodの構成ファイルは次のとおりです:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
これで、このPodを実行するときに、次のコマンドを実行して、各ログストリームに個別にアクセスできます:
kubectl logs counter count-log-1
出力は次のようになります:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
出力は次のようになります:
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
クラスターにインストールされているノードレベルのエージェントは、それ以上の設定を行わなくても、これらのログストリームを自動的に取得します。必要があれば、ソースコンテナに応じてログをパースするようにエージェントを構成できます。
CPUとメモリーの使用量が少ない(CPUの場合は数ミリコアのオーダー、メモリーの場合は数メガバイトのオーダー)にも関わらず、ログをファイルに書き込んでからstdoutにストリーミングすると、ディスクの使用量が2倍になる可能性があることに注意してください。単一のファイルに書き込むアプリケーションがある場合は、ストリーミングサイドカーコンテナアプローチを実装するのではなく、/dev/stdoutを宛先として設定することをおすすめします。
サイドカーコンテナを使用して、アプリケーション自体ではローテーションできないログファイルをローテーションすることもできます。このアプローチの例は、logrotateを定期的に実行する小さなコンテナです。しかし、stdoutとstderrを直接使い、ローテーションと保持のポリシーをkubeletに任せることをおすすめします。
ロギングエージェントを使用したサイドカーコンテナ
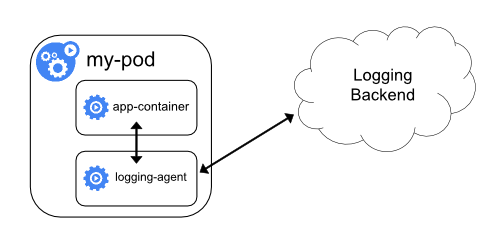
ノードレベルロギングのエージェントが、あなたの状況に必要なだけの柔軟性を備えていない場合は、アプリケーションで実行するように特別に構成した別のロギングエージェントを使用してサイドカーコンテナを作成できます。
kubectl logsを使用してこれらのログにアクセスすることができません。
ロギングエージェントを使用したサイドカーコンテナを実装するために使用できる、2つの構成ファイルを次に示します。最初のファイルには、fluentdを設定するためのConfigMapが含まれています。
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
2番目のファイルは、fluentdを実行しているサイドカーコンテナを持つPodを示しています。Podは、fluentdが構成データを取得できるボリュームをマウントします。
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: registry.k8s.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
サンプル構成では、fluentdを任意のロギングエージェントに置き換えて、アプリケーションコンテナ内の任意のソースから読み取ることができます。
アプリケーションから直接ログを公開する
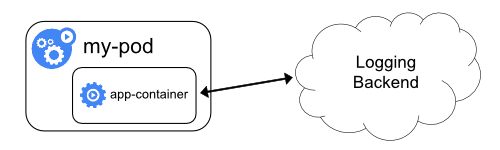
すべてのアプリケーションから直接ログを公開または送信するクラスターロギングは、Kubernetesのスコープ外です。
6 - システムログ
システムコンポーネントのログは、クラスター内で起こったイベントを記録します。このログはデバッグのために非常に役立ちます。ログのverbosityを設定すると、ログをどの程度詳細に見るのかを変更できます。ログはコンポーネント内のエラーを表示する程度の荒い粒度にすることも、イベントのステップバイステップのトレース(HTTPのアクセスログ、Podの状態の変更、コントローラーの動作、スケジューラーの決定など)を表示するような細かい粒度に設定することもできます。
klog
klogは、Kubernetesのログライブラリです。klogは、Kubernetesのシステムコンポーネント向けのログメッセージを生成します。
klogの設定に関する詳しい情報については、コマンドラインツールのリファレンスを参照してください。
klogネイティブ形式の例:
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
構造化ログ
Kubernetes v1.19 [alpha]
構造化ログへのマイグレーションは現在進行中の作業です。このバージョンでは、すべてのログメッセージが構造化されているわけではありません。ログファイルをパースする場合、JSONではないログの行にも対処しなければなりません。
ログの形式と値のシリアライズは変更される可能性があります。
構造化ログは、ログメッセージに単一の構造を導入し、プログラムで情報の抽出ができるようにするものです。構造化ログは、僅かな労力とコストで保存・処理できます。新しいメッセージ形式は後方互換性があり、デフォルトで有効化されます。
構造化ログの形式:
<klog header> "<message>" <key1>="<value1>" <key2>="<value2>" ...
例:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod="kube-system/kubedns" status="ready"
JSONログ形式
Kubernetes v1.19 [alpha]
JSONの出力は多数の標準のklogフラグをサポートしていません。非対応のklogフラグの一覧については、コマンドラインツールリファレンスを参照してください。
すべてのログがJSON形式で書き込むことに対応しているわけではありません(たとえば、プロセスの開始時など)。ログのパースを行おうとしている場合、JSONではないログの行に対処できるようにしてください。
フィールド名とJSONのシリアライズは変更される可能性があります。
--logging-format=jsonフラグは、ログの形式をネイティブ形式klogからJSON形式に変更します。以下は、JSONログ形式の例(pretty printしたもの)です。
{
"ts": 1580306777.04728,
"v": 4,
"msg": "Pod status updated",
"pod":{
"name": "nginx-1",
"namespace": "default"
},
"status": "ready"
}
特別な意味を持つキー:
ts- Unix時間のタイムスタンプ(必須、float)v- verbosity (必須、int、デフォルトは0)err- エラー文字列 (オプション、string)msg- メッセージ (必須、string)
現在サポートされているJSONフォーマットの一覧:
ログのサニタイズ
Kubernetes v1.20 [alpha]
--experimental-logging-sanitizationフラグはklogのサニタイズフィルタを有効にします。有効にすると、すべてのログの引数が機密データ(パスワード、キー、トークンなど)としてタグ付けされたフィールドについて検査され、これらのフィールドのログの記録は防止されます。
現在ログのサニタイズをサポートしているコンポーネント一覧:
- kube-controller-manager
- kube-apiserver
- kube-scheduler
- kubelet
ログのverbosityレベル
-vフラグはログのverbosityを制御します。値を増やすとログに記録されるイベントの数が増えます。値を減らすとログに記録されるイベントの数が減ります。verbosityの設定を増やすと、ますます多くの深刻度の低いイベントをログに記録するようになります。verbosityの設定を0にすると、クリティカルなイベントだけをログに記録します。
ログの場所
システムコンポーネントには2種類あります。コンテナ内で実行されるコンポーネントと、コンテナ内で実行されないコンポーネントです。たとえば、次のようなコンポーネントがあります。
- Kubernetesのスケジューラーやkube-proxyはコンテナ内で実行されます。
- kubeletやDockerのようなコンテナランタイムはコンテナ内で実行されません。
systemdを使用しているマシンでは、kubeletとコンテナランタイムはjournaldに書き込みを行います。それ以外のマシンでは、/var/logディレクトリ内の.logファイルに書き込みます。コンテナ内部のシステムコンポーネントは、デフォルトのログ機構をバイパスするため、常に/var/logディレクトリ内の.logファイルに書き込みます。コンテナのログと同様に、/var/logディレクトリ内のシステムコンポーネントのログはローテートする必要があります。kube-up.shスクリプトによって作成されたKubernetesクラスターでは、ログローテーションはlogrotateツールで設定されます。logrotateツールはログを1日ごとまたはログのサイズが100MBを超えたときにローテートします。
次の項目
- Kubernetesのログのアーキテクチャについて読む。
- 構造化ログについて読む。
- ログの深刻度の慣習について読む。
7 - Kubernetesのプロキシー
このページではKubernetesと併用されるプロキシーについて説明します。
プロキシー
Kubernetesを使用する際に、いくつかのプロキシーを使用する場面があります。
-
- ユーザーのデスクトップ上かPod内で稼働します
- ローカルホストのアドレスからKubernetes apiserverへのプロキシーを行います
- クライアントからプロキシー間ではHTTPを使用します
- プロキシーからapiserverへはHTTPSを使用します
- apiserverの場所を示します
- 認証用のヘッダーを追加します
-
- apiserver内で動作する踏み台となります
- これがなければ到達不可能であるクラスターIPへ、クラスターの外部からのユーザーを接続します
- apiserverのプロセス内で稼働します
- クライアントからプロキシー間ではHTTPSを使用します(apiserverの設定により、HTTPを使用します)
- プロキシーからターゲット間では利用可能な情報を使用して、プロキシーによって選択されたHTTPかHTTPSのいずれかを使用します
- Node、Pod、Serviceへ到達するのに使えます
- Serviceへ到達するときは負荷分散を行います
-
- 各ノード上で稼働します
- UDP、TCP、SCTPをプロキシーします
- HTTPを解釈しません
- 負荷分散機能を提供します
- Serviceへ到達させるためのみに使用されます
-
apiserverの前段にあるプロキシー/ロードバランサー:
- 実際に存在するかどうかと実装はクラスターごとに異なります(例: nginx)
- 全てのクライアントと、1つ以上のapiserverの間に位置します
- 複数のapiserverがあるときロードバランサーとして稼働します
-
外部サービス上で稼働するクラウドロードバランサー:
- いくつかのクラウドプロバイダーによって提供されます(例: AWS ELB、Google Cloud Load Balancer)
LoadBalancerというtypeのKubernetes Serviceが作成されたときに自動で作成されます- たいていのクラウドロードバランサーはUDP/TCPのみサポートしています
- SCTPのサポートはクラウドプロバイダーのロードバランサーの実装によって異なります
- ロードバランサーの実装はクラウドプロバイダーによって異なります
Kubernetesユーザーのほとんどは、最初の2つのタイプ以外に心配する必要はありません。クラスター管理者はそれ以外のタイプのロードバランサーを正しくセットアップすることを保証します。
リダイレクトの要求
プロキシーはリダイレクトの機能を置き換えました。リダイレクトの使用は非推奨となります。
8 - アドオンのインストール
アドオンはKubernetesの機能を拡張するものです。
このページでは、利用可能なアドオンの一部の一覧と、それぞれのアドオンのインストール方法へのリンクを提供します。この一覧は、すべてを網羅するものではありません。
ネットワークとネットワークポリシー
- ACIは、統合されたコンテナネットワークとネットワークセキュリティをCisco ACIを使用して提供します。
- Antreaは、L3またはL4で動作して、Open vSwitchをネットワークデータプレーンとして活用する、Kubernetes向けのネットワークとセキュリティサービスを提供します。
- Calicoはネットワークとネットワークポリシーのプロバイダーです。Calicoは、BGPを使用または未使用の非オーバーレイおよびオーバーレイネットワークを含む、フレキシブルなさまざまなネットワークオプションをサポートします。Calicoはホスト、Pod、そして(IstioとEnvoyを使用している場合には)サービスメッシュ上のアプリケーションに対してネットワークポリシーを強制するために、同一のエンジンを使用します。
- CanalはFlannelとCalicoをあわせたもので、ネットワークとネットワークポリシーを提供します。
- Ciliumは、L3のネットワークとネットワークポリシーのプラグインで、HTTP/API/L7のポリシーを透過的に強制できます。ルーティングとoverlay/encapsulationモードの両方をサポートしており、他のCNIプラグイン上で機能できます。
- CNI-Genieは、KubernetesをCalico、Canal、Flannel、Weaveなど選択したCNIプラグインをシームレスに接続できるようにするプラグインです。
- Contivは、さまざまなユースケースと豊富なポリシーフレームワーク向けに設定可能なネットワーク(BGPを使用したネイティブのL3、vxlanを使用したオーバーレイ、古典的なL2、Cisco-SDN/ACI)を提供します。Contivプロジェクトは完全にオープンソースです。インストーラーはkubeadmとkubeadm以外の両方をベースとしたインストールオプションがあります。
- Contrailは、Tungsten Fabricをベースにしている、オープンソースでマルチクラウドに対応したネットワーク仮想化およびポリシー管理プラットフォームです。ContrailおよびTungsten Fabricは、Kubernetes、OpenShift、OpenStack、Mesosなどのオーケストレーションシステムと統合されており、仮想マシン、コンテナ/Pod、ベアメタルのワークロードに隔離モードを提供します。
- Flannelは、Kubernetesで使用できるオーバーレイネットワークプロバイダーです。
- Knitterは、1つのKubernetes Podで複数のネットワークインターフェイスをサポートするためのプラグインです。
- Multusは、すべてのCNIプラグイン(たとえば、Calico、Cilium、Contiv、Flannel)に加えて、SRIOV、DPDK、OVS-DPDK、VPPをベースとするKubernetes上のワークロードをサポートする、複数のネットワークサポートのためのマルチプラグインです。
- OVN-Kubernetesは、Open vSwitch(OVS)プロジェクトから生まれた仮想ネットワーク実装であるOVN(Open Virtual Network)をベースとする、Kubernetesのためのネットワークプロバイダーです。OVN-Kubernetesは、OVSベースのロードバランサーおよびネットワークポリシーの実装を含む、Kubernetes向けのオーバーレイベースのネットワーク実装を提供します。
- Nodusは、OVNベースのCNIコントローラープラグインで、クラウドネイティブベースのService function chaining(SFC)を提供します。
- NSX-T Container Plug-in(NCP)は、VMware NSX-TとKubernetesなどのコンテナオーケストレーター間のインテグレーションを提供します。また、NSX-Tと、Pivotal Container Service(PKS)とOpenShiftなどのコンテナベースのCaaS/PaaSプラットフォームとのインテグレーションも提供します。
- Nuageは、Kubernetes Podと非Kubernetes環境間で可視化とセキュリティモニタリングを使用してポリシーベースのネットワークを提供するSDNプラットフォームです。
- Romanaは、NetworkPolicy APIもサポートするPodネットワーク向けのL3のネットワークソリューションです。
- Weave Netは、ネットワークパーティションの両面で機能し、外部データベースを必要とせずに、ネットワークとネットワークポリシーを提供します。
サービスディスカバリー
可視化と制御
- DashboardはKubernetes向けのダッシュボードを提供するウェブインターフェイスです。
- Weave Scopeは、コンテナ、Pod、Serviceなどをグラフィカルに可視化するツールです。Weave Cloud accountと組み合わせて使うか、UIを自分でホストして使います。
インフラストラクチャ
- KubeVirtは仮想マシンをKubernetes上で実行するためのアドオンです。通常、ベアメタルのクラスターで実行します。
- node problem detectorはLinuxノード上で動作し、システムの問題をEventまたはノードのConditionとして報告します。
レガシーなアドオン
いくつかのアドオンは、廃止されたcluster/addonsディレクトリに掲載されています。
よくメンテナンスされたアドオンはここにリンクしてください。PRを歓迎しています。